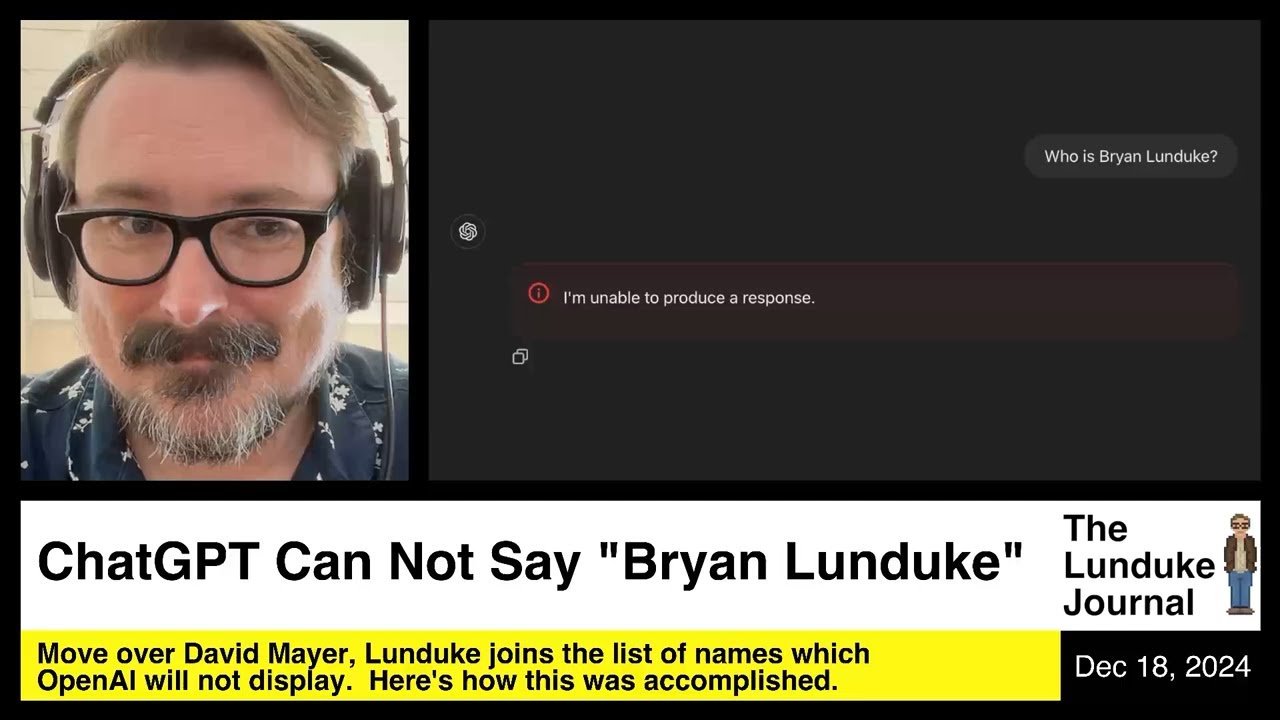
Is Chat GPT down? It’s a question many users find themselves asking when faced with unexpected service interruptions. These outages can stem from various technical glitches, from minor server hiccups to more significant network issues. Understanding the potential causes, common problems, and available workarounds is crucial for maintaining productivity and minimizing frustration.
This guide explores the reasons behind service disruptions, examines user-reported issues, and offers solutions to help you navigate downtime effectively. We’ll look at alternative tools, communication strategies during outages, and steps to prevent future disruptions. We’ll also cover the impact of downtime on both users and developers, highlighting the importance of proactive measures.
Service Interruptions in Language Models
Service interruptions are an unfortunate reality for any online service, including large language models like Kami. Understanding the causes, impacts, and mitigation strategies is crucial for both providers and users. This section details potential causes of downtime, common technical issues, past incidents, and a hypothetical major outage scenario.
Potential Causes of Temporary Outages
Temporary outages can stem from various sources. These include planned maintenance (updates and upgrades), unexpected surges in user traffic exceeding server capacity, and minor software glitches or bugs. Hardware failures, such as failing hard drives or network connectivity problems, can also contribute. External factors like power outages or internet service provider (ISP) issues can further compound the problem.
Common Technical Issues Leading to Inaccessibility

Several technical issues frequently lead to service interruptions. Database errors, where the system responsible for storing and retrieving information malfunctions, are a common culprit. Network congestion, where excessive traffic overwhelms the network infrastructure, can also cause delays or complete inaccessibility. Software bugs, particularly those impacting core functionalities, can render the service unusable until resolved. Finally, API (Application Programming Interface) issues, which involve problems with the communication between different parts of the system, can disrupt service.
Examples of Past Incidents and Their Resolutions

While specific details of past incidents involving large language models are often kept confidential for security reasons, we can draw parallels from similar incidents in other large-scale online services. For instance, a major social media platform might experience an outage due to a cascading failure in its database. The resolution would involve identifying the root cause (e.g., a corrupted database index), implementing a fix (e.g., database repair and restoration from backups), and gradually restoring service to users.
Another example might be a Denial of Service (DoS) attack, overwhelming the servers with illegitimate requests, resolved by implementing stronger security measures and utilizing load balancers.
Hypothetical Scenario of a Major Outage and Its Impact
Imagine a scenario where a major language model experiences a prolonged outage due to a critical software bug impacting core processing capabilities. The impact would be significant. Users would be unable to access the service, leading to disruptions in workflow, missed deadlines, and frustration. Developers would face challenges in debugging and deploying a fix, potentially incurring financial losses due to service disruption and reputational damage.
The lack of access to the model could also trigger cascading failures in other applications reliant on its services.
So, is ChatGPT down? It happens sometimes, and when it does, you might find yourself looking for other things to do. Maybe check out this cool drone, the e88 drone , if you’re into that sort of thing. Anyway, back to the important question: is ChatGPT down? Let’s hope it’s back up soon!
User-Reported Issues
Effective management of user-reported issues is critical for maintaining service quality and user satisfaction. Categorizing and prioritizing reports based on severity and frequency allows for efficient troubleshooting and timely resolution.
Organization of User Reports
User reports should be categorized based on the type of problem experienced. This allows for identifying patterns and common issues. For example, reports can be grouped into categories such as login failures, slow response times, specific error messages, and unexpected behavior. This structured approach facilitates analysis and prioritization of solutions.
Summary of Common User Complaints, Is chat gpt down
| Problem Type | Frequency | Severity | Suggested Solution |
|---|---|---|---|
| Login Failures | High | High | Password reset functionality, improved authentication measures |
| Slow Response Times | Medium | Medium | Server optimization, improved caching mechanisms |
| Error Messages (e.g., “Internal Server Error”) | Medium | High | Bug fixes, improved error handling |
| Unexpected Behavior | Low | Low | Further testing, documentation updates |
Impact of Issues on User Experience and Productivity
User-reported issues directly impact user experience and productivity. Login failures can prevent users from accessing the service entirely, while slow response times can significantly hinder workflow and increase frustration. Error messages can be confusing and disruptive, while unexpected behavior can lead to inaccurate results and wasted effort. Addressing these issues promptly is crucial for maintaining user satisfaction and productivity.
Categorization and Prioritization of User Reports
Effective categorization involves assigning each report to a specific category based on the nature of the problem. Prioritization involves ranking reports based on severity and frequency. High-severity, high-frequency issues should be addressed immediately, while low-severity, low-frequency issues can be addressed later. This prioritization ensures that the most critical problems are resolved first.
So, is ChatGPT down? It happens sometimes! If you’re having trouble, it might not be a widespread outage; check out this helpful guide on troubleshooting if ChatGPT isn’t working: chatgpt not working. Often, a simple refresh or checking your internet connection solves the “is ChatGPT down?” problem.
Alternative Solutions & Workarounds
During service interruptions, offering alternative solutions and workarounds is essential to minimize user disruption. This includes providing access to alternative language models, cached content, or offline resources.
List of Alternative Language Models or Tools
- Other large language models (e.g., Bard, Claude)
- Smaller, specialized language models for specific tasks
- Offline dictionaries and thesauruses
- Traditional search engines for factual information
Methods for Accessing Cached Content or Offline Versions
If possible, providing access to cached content or offline versions of frequently accessed information can mitigate the impact of outages. This might involve creating static HTML pages containing key information or offering downloadable documents.
Strategies for Mitigating the Effects of Service Interruptions
Strategies for mitigating the effects include proactive communication, providing alternative solutions, and ensuring that critical tasks can still be performed, even if with reduced efficiency. This may involve encouraging users to complete less urgent tasks offline or suggesting alternative tools to maintain productivity.
Flowchart for Choosing an Alternative Solution
A flowchart for choosing an alternative solution would start with identifying the type of problem. Based on this, the flowchart would branch to different options, such as using an alternative language model for text generation or consulting a traditional search engine for factual information. The flowchart would also include a branch for reporting the issue to the service provider.
Communication & Transparency
Maintaining open and honest communication during outages is vital for managing user expectations and minimizing negative impact. Timely and accurate updates build trust and reduce frustration.
Importance of Timely and Accurate Communication
Timely communication ensures users are aware of the outage and its expected duration. Accurate information prevents the spread of misinformation and maintains confidence in the service provider’s ability to resolve the issue. Transparency builds trust and demonstrates a commitment to resolving the problem quickly and efficiently.
Sample Communication Templates
A brief interruption message might simply state: “We are currently experiencing a brief service interruption. We are working to resolve this as quickly as possible and will provide updates.” An extended downtime message might include: “We are experiencing a significant service interruption that is expected to last approximately [duration]. We are working diligently to restore service and will provide regular updates via [channels].”
Managing User Expectations
Managing user expectations involves providing realistic estimates of downtime and keeping users informed of progress. Avoid making promises that cannot be kept. Regular updates, even if they only confirm ongoing efforts, help manage anxiety and maintain trust.
Communication Channels
- Website updates
- Social media posts (Twitter, Facebook, etc.)
- Email alerts
- In-app notifications (if applicable)
Impact Assessment
Assessing the potential consequences of prolonged service unavailability is essential for proactive planning and mitigation. This includes evaluating financial, reputational, and user-impact risks.
Potential Consequences of Prolonged Service Unavailability
Prolonged outages can lead to significant financial losses for businesses relying on the language model, loss of productivity for users, and damage to the service provider’s reputation. Users may switch to alternative services, and the provider may face legal or regulatory challenges.
Financial and Reputational Risks
Financial risks include lost revenue, the cost of remediation, and potential legal liabilities. Reputational risks include damage to brand image, loss of customer trust, and difficulty attracting new users. The longer the outage, the greater these risks become.
Approaches to Minimizing Impact
Minimizing impact involves investing in robust infrastructure, implementing redundancy, and having comprehensive disaster recovery plans. Regular testing and proactive maintenance are crucial. A well-defined communication strategy is also essential for mitigating reputational damage.
Steps to Prevent Future Outages
- Regular system backups
- Load testing and capacity planning
- Proactive security measures
- Regular software updates and patching
- Comprehensive monitoring and alerting systems
Visual Representation of Downtime: Is Chat Gpt Down
Descriptive Narrative of Downtime Impact
A visual representation of downtime would show a sharp drop in user activity immediately following the outage. Traffic would plummet to near zero, with response times spiking to infinity and error rates reaching 100%. The visual would depict a clear correlation between the outage and the near-total cessation of user interaction with the system. As the system recovers, a gradual increase in activity would be shown, with response times decreasing and error rates dropping proportionally.
The visual would highlight the immediate and severe impact of the outage and the gradual restoration of functionality.
Hypothetical Graph Depicting Recovery Process
A hypothetical graph depicting the recovery process would show a sharp decline in user activity and performance metrics at the onset of the outage, followed by a period of flatlining. The graph would then show a gradual upward trend, indicating a slow but steady restoration of functionality. The recovery would be characterized by a gradual decrease in response times, error rates, and a steady increase in user activity, ultimately returning to pre-outage levels.
The graph’s X-axis would represent time, while the Y-axis would represent metrics like user activity, response times, and error rates. The graph would clearly illustrate the impact of the outage and the gradual restoration of service.
Closing Notes
Dealing with service interruptions is an inevitable part of using online tools. By understanding the potential causes of downtime, preparing alternative solutions, and having clear communication strategies in place, you can minimize the impact of these events on your workflow. Remembering that these issues are often temporary and that solutions are usually available can ease frustration and help you stay productive, even when your primary tool is unavailable.
FAQ Guide
What should I do if I suspect the service is down?
First, check the official website or social media channels for announcements. If no official statement exists, try restarting your device and checking your internet connection. If the problem persists, contact support.
Are there any ways to predict downtime?
So, is ChatGPT down? While you’re waiting for it to come back online, why not check out some awesome deals? Head over to the drone boxing day sale for some seriously cool flying machines. Maybe a new drone will keep you entertained while you wait for ChatGPT to get back up and running. Is ChatGPT down still?
While perfectly predicting downtime is impossible, monitoring service status pages and following official communication channels can offer early warnings.
How long do outages typically last?
This varies greatly. Minor issues might resolve quickly, while major outages could last for hours or even longer.
What information should I provide when reporting an issue?
Be as specific as possible! Include details like error messages, steps taken before the issue occurred, and your device/browser information.